Как одна правка в базе данных обрушила пол-интернета
Утро, когда «сломался интернет»
Утро 18 ноября 2025 года для миллионов людей по всему миру выглядело одинаково странно.
Лента X (бывший Twitter) не загружается, ChatGPT и другие ИИ-сервисы отваливаются с ошибками, Spotify молчит, Canva не открывается, сайты транспортных компаний и госорганов ведут себя так, будто интернета нет вовсе. На многих страницах — типичная оранжевая заглушка Cloudflare с ошибкой 5xx.
Под ударом, по оценкам СМИ и самих компаний, оказались:
- X, ChatGPT, Claude, Perplexity;
- Spotify, Canva, Dropbox, Shopify;
- онлайн-игры вроде League of Legends;
- Coinbase и другие финтех-сервисы;
- общественный транспорт и госструктуры — от NJ Transit в США до французской SNCF и британских регуляторов FCA и MI5.
В первые часы соцсети и часть медиа заговорили о гигантской кибератаке. Но уже в тот же день Cloudflare опубликовала технический разбор (post-mortem) и честно признала: никаких хакеров, мы сами сломали себе сеть одной неудачной правкой в базе данных. Давайте разберёмся, что произошло, почему это случилось и как избежать таких ситуаций в будущем.
Что такое Cloudflare и почему его падение ощущается как конец света
Чтобы понять масштаб, нужно разобраться, чем вообще занимается Cloudflare.
Cloudflare — это крупный интернет-инфраструктурный провайдер. Его часто описывают как «CDN и щит для веба», но по сути это целая «облачная сеть связности»:
Основные функции Cloudflare
CDN (Content Delivery Network, сеть доставки контента)
Распределённые по миру серверы, которые отдают пользователям копии статического содержимого (картинки, скрипты, стили) с ближайшей точки. Результат — сайты грузятся быстрее.
DNS-хостинг
Обслуживание записей «домен → IP-адрес» с высокой отказоустойчивостью и низкой задержкой. DNS (Domain Name System) — это, по сути, «телефонная книга интернета», которая переводит понятные человеку адреса вроде example.com в числовые IP-адреса серверов.
Обратный прокси (reverse proxy)
Запрос пользователя идёт сначала на узел Cloudflare, и только потом — на исходный сервер сайта. По дороге можно:
- отфильтровать вредный трафик;
- закешировать ответы для ускорения;
- спрятать реальный IP исходного сервера сайта.
Защита и фильтрация трафика
DDoS-защита (защита от массовых атак переполнением запросами), веб-файрвол (WAF — Web Application Firewall), Bot Management (управление ботами — борьба с вредоносными автоматическими запросами), защита API, системы аутентификации (Cloudflare Access, Turnstile) и т.д.
По оценкам Cloudflare и независимых аналитиков, через инфраструктуру компании проходит трафик примерно пятой части всех сайтов в интернете.
Поэтому когда Cloudflare «падает», это выглядит как частичный «блэкаут» интернета: тысячи независимых сайтов оказываются завязаны на одну точку отказа.
Как одна правка в ClickHouse превратилась в глобальную аварию
Разберёмся, что именно пошло не так — по шагам, но без лишнего жаргона.
Кто за что отвечает внутри Cloudflare
Каждый HTTP(S)-запрос к сайту за Cloudflare проходит примерно такой путь:
TLS/HTTP-слой — устанавливается защищённое соединение (HTTPS), разбираются заголовки и путь запроса.
Core proxy (основной прокси, FL / FL2) — главный «конвейер», написанный на Rust, где по очереди отрабатывают модули:
- кеш;
- система защиты от DDoS;
- WAF (веб-файрвол);
- Bot Management (управление ботами);
- переадресация трафика на Workers, R2 и т.п.
Обращение к origin-серверу — если ответа нет в кеше, FL/FL2 устанавливает соединение с исходным сервером. Для этого Cloudflare использует отдельную подсистему/proxy-инфраструктуру, построенную на Pingora (Rust-фреймворк и HTTP-прокси, который сейчас заменил NGINX и обслуживает значительную часть трафика).
Bot Management — один из этих модулей. Это система, которая с помощью машинного обучения пытается определить, кто перед нами: живой человек, «хороший» бот (например, поисковый робот Google) или вредный бот (скрейпер, программа для взлома паролей и т.п.).
Модель принимает на вход набор признаков (features): технические характеристики запроса — заголовки, поведение соединения, параметры клиента, IP-метаданные и т.д. Эти признаки описываются в специальном конфигурационном feature-файле, который пересобирается каждые несколько минут и рассылается на все узлы сети.
Описание признаков хранится в базе ClickHouse — популярной аналитической СУБД, хорошо подходящей для больших объёмов логов и телеметрии.
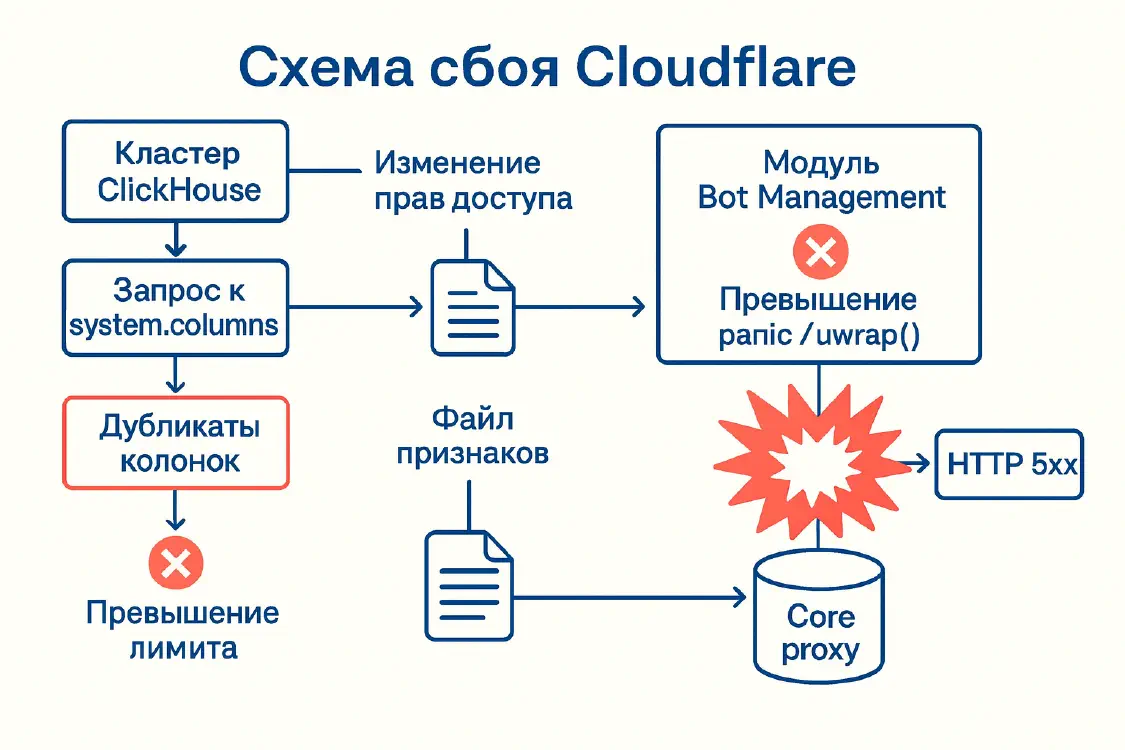
Шаг 1. Изменение прав доступа в ClickHouse
18 ноября около 11:05 UTC инженеры Cloudflare внесли изменение в схему прав доступа в одном из ClickHouse-кластеров. Цель была правильная: сделать работу распределённых запросов безопаснее, чтобы вместо общего сервисного аккаунта они выполнялись от конкретных пользователей — с более точными лимитами.
До изменения пользователи фактически видели только таблицы в базе default. После — стали «видеть» метаданные таблиц в служебной базе r0, где хранятся реальные данные по шардам (частям распределённой базы).
Шаг 2. Старый запрос — новые последствия
Проблема в том, что код, который собирал список признаков для Bot Management, ходил не в саму таблицу с данными, а в системную таблицу метаданных system.columns:
SELECT name, type
FROM system.columns
WHERE table = 'http_requests_features'
ORDER BY name;
В system.columns для каждой колонки есть и имя базы (database), и имя таблицы (table). Запрос фильтрует только по имени таблицы. Никакого условия по database здесь нет — ни WHERE database = 'default', ни другого ограничения.
Пока у пользователя были права только на базу default, это было «безопасным» допущением: из system.columns возвращались только колонки этой базы, и запрос работал как задумано.
После изменения прав стали видны и служебные таблицы в базе r0. Для них тоже есть таблица http_requests_features, поэтому запрос начал возвращать дубликаты колонок — сразу из default и из r0.
В результате количество признаков, попадающих в feature-файл, резко выросло (по сути — больше чем вдвое). Этот файл по-прежнему пересобирался каждые несколько минут и рассылался по всей сети Cloudflare — только теперь уже с раздутым списком признаков.
Шаг 3. Жёсткий лимит и «паника» в прокси
Модуль Bot Management внутри прокси рассчитывал, что признаков не будет слишком много. Для оптимизации памяти там стоял лимит: не больше 200 признаков — с приличным запасом относительно фактических ~60.
Когда «раздутый» конфиг с превышением лимита попал на узлы, сработал защитный код на Rust, на котором написан прокси. Проверка выглядела примерно так: если признаков больше 200 — возвращается ошибка. Но дальше поверх неё использовался небезопасный приём unwrap() — по сути команда «мне обещали, что ошибки не будет, можно не проверять».
В Rust это приводит к panic — аварийному завершению потока, аналог жёсткого assert в других языках программирования. Паника внутри рабочего потока core proxy означает: поток, обслуживающий запросы, просто падает. А пользователь видит HTTP 5xx — ошибку сервера.
Часть клиентов уже была мигрирована на новый движок FL2 — там падал сам прокси и пользователи получали ошибки. На старом FL (где код вёл себя иначе) запросы не падали, но бот-оценки становились некорректными (всё получало «0»), ломая антибот-правила.
Шаг 4. Почему система то падала, то вставала
Ситуацию сильно усложнило то, что кластер ClickHouse обновлялся постепенно, а не «разом».
Запрос, генерирующий feature-файл, то попадал на уже обновлённую ноду (узел сети, давая «плохой» конфиг), то на старую (давая «хороший»). В итоге:
- каждые несколько минут по сети рассылался то нормальный, то ошибочный конфиг;
- прокси то «оживал», то снова уходил в 5xx.
Снаружи это выглядело очень похоже на масштабную DDoS-атаку: всплески ошибок, нестабильность, плюс в это же время по совпадению перестала работать статус-страница Cloudflare (она вообще размещена у стороннего провайдера), что только усилило ощущение, что «нас атакуют со всех сторон».
Шаг 5. Как удалось остановить аварию
По официальному таймлайну Cloudflare:
- 11:05 UTC — выкатывается изменение прав в ClickHouse.
- 11:20–11:28 — начинаются массовые 5xx-ошибки, пользователи видят страницы с ошибкой Cloudflare.
- 11:32–13:05 — команда ищет причину, сначала подозревая проблемы в Workers KV и аномальный трафик (версии про DDoS).
- 13:05 — для Workers KV и Cloudflare Access включают обходной путь, чтобы снизить влияние.
- 14:24–14:30 — останавливают генерацию и распространение нового feature-файла Bot Management, в очередь вручную кладут последнюю «правильную» версию и перезапускают core proxy; основной трафик приходит в норму.
- 17:06 — добивают «длинный хвост», перезапуская застрявшие сервисы; Cloudflare заявляет, что все системы работают нормально.
В своём посте CEO Мэттью Принс называет это «худшим нашим сбоем с 2019 года» и отдельно подчёркивает, что никакой атаки не было — только внутренняя конфигурационная ошибка.
Это не была кибератака
Несмотря на первые заголовки и догадки, Cloudflare в официальном разборе говорит довольно однозначно:
«Проблема не была вызвана ни прямой, ни косвенной кибератакой или злонамеренной активностью. Всё началось с изменения прав в нашей базе данных».
Крупные медиа (Financial Times, AP и др.) со ссылкой на Cloudflare подтверждают: речь о внутренней ошибке конфигурации и бага в модуле Bot Management, который не выдержал необычно большого конфигурационного файла.
Кто пострадал и каковы последствия
Разные источники оценивают масштаб так: десятки тысяч сайтов и сервисов по всему миру испытывали от серьёзной деградации до полной недоступности. Среди ключевых пострадавших:
- X, ChatGPT, Claude, Perplexity;
- Spotify, Canva, Dropbox, Shopify;
- League of Legends и другие онлайн-игры;
- Coinbase, Moody’s и другие финансовые сервисы;
- транспортные системы (NJ Transit, SNCF) и регуляторы (FCA, MI5).
Как это выглядело для пользователей
- оранжевые страницы Cloudflare с кодом 5xx;
- «вечная» загрузка без ответа;
- невозможность залогиниться (когда страдали Turnstile и Cloudflare Access).
Последствия для бизнеса
- задержки онлайн-продаж и неработающие платежи;
- сорванные мероприятия (пример — сорванный вебкаст квартальной отчётности Home Depot);
- репутационный удар по Cloudflare и по компаниям, которые завязаны на одного инфраструктурного провайдера (акции Cloudflare в день инцидента просели).
На уровне индустрии инцидент стал ещё одним напоминанием о хрупкости централизованной инфраструктуры — после недавних сбоев, связанных, например, с AWS, Microsoft Azure или громким провалом обновления у CrowdStrike.
А что в России?
У нас Cloudflare сейчас не особо используется, поскольку Роскомнадзор предпринял массу усилий для этого. Давайте немного вспомним историю взаимодействия российских властей и Cloudflare. Опираться буду на официальные заявления и профильные издания, а не на пересказы.
TLS ECH и претензии РКН
Осенью 2024 года Cloudflare включила по умолчанию поддержку TLS ECH (Encrypted Client Hello) для клиентов CDN.
Что такое TLS ECH?
- При установке HTTPS-соединения клиент сначала отправляет сообщение Client Hello — начальное «рукопожатие» с сервером.
- В нём, среди прочего, содержится поле SNI (Server Name Indication) — имя домена, к которому идёт запрос (например,
blocked-site.com). - ECH шифрует эту часть, и провайдеру становится сложнее понять, к какому именно домену обращается пользователь — он видит только, что идёт подключение к Cloudflare.
Для пользователя это плюс к приватности. Для российской системы блокировок доменов — серьёзная проблема: блокировать «по имени сайта» на уровне оператора связи становится существенно сложнее.
2 апреля 2025 года Роскомнадзор через свои структуры рекомендовал владельцам российских сайтов отказаться от использования TLS ECH в Cloudflare или вообще от сервиса, мотивируя это тем, что ECH «может использоваться для обхода ограничений доступа к запрещённому контенту и нарушает российское законодательство».
В формулировках РКН ECH прямо называют «средством обхода блокировок».
Внесение Cloudflare в реестр ОРИ
В феврале 2025 года Роскомнадзор принудительно внёс Cloudflare в реестр организаторов распространения информации (ОРИ).
Что такое ОРИ? Это статус для интернет-компаний, который накладывает на них дополнительные обязательства по российскому законодательству.
Это значит, что на сервис возложены обязанности:
- хранить данные российских пользователей в течение установленного срока;
- по запросу уполномоченных органов предоставлять информацию, включая переписку и трафик (в рамках российского законодательства об ОРИ).
До этого, по данным Интерфакса и Forbes, Cloudflare дважды штрафовали за неисполнение требований уведомить РКН о начале работы в статусе ОРИ.
Ограничение трафика: позиция Cloudflare и реакция РКН
С июня 2025 года начинается новый этап конфликта. По данным самой Cloudflare, с 9 июня 2025 года российские операторы связи начали систематически ограничивать доступ к сайтам и сервисам, защищённым Cloudflare.
Что такое ограничение трафика (throttling)?
Это когда интернет-провайдер искусственно замедляет или обрезает передачу данных для определённых сайтов или сервисов, делая их работу крайне медленной или невозможной.
В официальном блоге компания пишет, что:
- соединения из России до ресурсов за Cloudflare ограничиваются на уровне местных интернет-провайдеров (ISP);
- анализ внутренних данных и внешние отчёты показывают, что во многих случаях передаётся только первые ~16 КБ данных, после чего соединение обрывается;
- такая тактика делает современные сайты «практически непригодными к использованию» — страница может начать загружаться, но не успевает подтянуть стили, скрипты и динамический контент.
Для сравнения: обычная веб-страница весит от нескольких сотен килобайт до нескольких мегабайт, так что ограничение в 16 КБ фактически делает нормальную работу невозможной.
Эту картину подтверждают разборы в профильных медиа (BleepingComputer, SecurityBoulevard, Cybernews и др.), опирающиеся на те же технические детали: ограничение объёма данных примерно до 16 КБ, рост числа разрывов TCP-соединений и ошибок HTTP/3.
Роскомнадзор, в свою очередь, через прессу отрицает причастность к перебоям и выдвигает версию о «технических проблемах самого Cloudflare», параллельно рекомендуя компаниям использовать инфраструктуру российских хостинг-провайдеров.
Как бы там ни было, факт, который обе стороны по сути признают косвенно: доступ к сайтам за Cloudflare из России серьёзно деградировал с июня 2025 года, и это не похоже на случайный сбой.
Что это значит для российского бизнеса
Профильные российские издания и эксперты оценивают последствия рекомендаций РКН и общего давления так:
- Cloudflare достаточно широко использовался в РФ — и как CDN, и как защита от DDoS;
- отказ от него требует:
- миграции на отечественные или альтернативные CDN и DNS-провайдеров;
- дополнительных расходов и времени на перестройку инфраструктуры;
- зачастую — падения уровня защиты и производительности, особенно для зарубежной аудитории.
Всё это накладывается на глобальные технические риски (такие, как эта авария), создавая для российских проектов двойную уязвимость: регуляторную и инфраструктурную одновременно.
Инженерные выводы: где именно всё сломалось
Если убрать эмоции, список причин аварии выглядит так.
1. Человеческая ошибка в конфигурации
Изменение прав доступа в ClickHouse было по замыслу полезным, но не были пересмотрены старые запросы, которые при новых правах начинают вести себя иначе. В частности, запрос к system.columns внезапно стал возвращать больше строк.
Это классический пример технического долга — когда код написан с упрощающими предположениями, которые когда-нибудь обязательно нарушатся.
2. Неявные допущения в коде
Запрос:
SELECT name, type FROM system.columns
WHERE table = 'http_requests_features' ORDER BY name;
рассчитывал на то, что база в системе фактически одна (default). Никаких фильтров по database не было, и это считалось «нормальным», пока мир вокруг (права доступа) не изменился. Это типичный пример хрупкого контракта: «мы уверены, что так будет всегда» — пока не стало по-другому.
3. Отсутствие жёсткой валидации внутренних конфигов
Feature-файл генерировался внутренним сервисом на основе данных ClickHouse, и считалось, что он заведомо корректен. Никаких строгих проверок на:
- максимальное количество признаков;
- максимальный размер файла;
- аномальные значения
на пути от генерации до раскатки по сети не было — или они были недостаточными. Валидация пользовательского ввода традиционно делается тщательно, а вот внутренние конфиги часто воспринимаются как «доверенные». Здесь это сыграло злую шутку.
4. Некорректное поведение модуля при ошибке
Лимит в 200 признаков — разумная защита от чрезмерного потребления памяти. Но при его превышении модуль не перешёл в режим graceful degradation (изящная деградация — мягкий отказ с сохранением основного функционала), а ушёл в panic:
panicв Rust — это намеренное аварийное завершение, сигнал «что-то пошло настолько не по плану, что продолжать нельзя»;- из-за
unwrap()на ошибочном результате рабочий поток прокси падал, и пользователи видели 5xx.
В идеале модуль бот-фильтрации в такой ситуации должен был:
- залогировать ошибку;
- отправить алерт в мониторинг;
- отключиться;
- пропустить трафик дальше без фильтрации.
Это как если бы при поломке стеклоочистителя на машине двигатель полностью заглох, вместо того чтобы продолжить ехать просто без «дворников».
5. Ограниченный контроль зоны поражения
Feature-файл пересобирался и раскатывался по сети часто и быстро, без достаточных канареечных этапов и автоматического отката по аномалиям.
Канареечное развёртывание (canary deployment) — это практика, когда обновление сначала выкатывается на небольшую часть серверов (1-5%), и если там всё работает нормально, только тогда распространяется дальше. Название пошло от шахтёрских канареек: птиц брали в шахты для раннего обнаружения ядовитых газов.
В результате ошибка в одном кластере ClickHouse достаточно быстро превратилась в проблему глобального масштаба, а не локальный инцидент в паре дата-центров.
Что обещает Cloudflare
Cloudflare уже публично пообещала:
- «ужесточить обработку конфигурационных файлов, даже если они генерируются самим Cloudflare»;
- добавить больше глобальных аварийных выключателей (kill-switches) для функциональных модулей;
- пересмотреть все сценарии отказа в core proxy;
- исключить ситуации, когда дампы памяти для отладки и отладочная телеметрия сами создают дополнительную нагрузку и усугубляют аварию.
Практические рекомендации
Для владельцев сайтов и продуктов
1. Не кладите все яйца в корзину одного провайдера
Если бизнес критично зависит от онлайна, стоит рассмотреть:
- multi-CDN (Cloudflare + ещё один CDN — например, Fastly, Akamai);
- резервного DNS-провайдера;
- возможность аварийного вывода домена из-под Cloudflare (прямой DNS на origin, второй фронт и т.п.).
2. Пропишите план на случай падения инфраструктурного провайдера
Не только Cloudflare, но и любого другого. В плане должно быть указано:
- кто принимает решение о переключении;
- какие записи DNS меняются и с какими TTL (время жизни DNS-записей — чем меньше TTL, тем быстрее изменения распространятся по интернету);
- какие сервисы спасаем в первую очередь (платежи, логин, API).
3. Следите не только за своими метриками, но и за статусом провайдеров
Подпишитесь на:
- статус-страницу Cloudflare;
- независимые мониторинги (Downdetector и аналоги);
- профессиональные чаты и сообщества DevOps/SRE.
Это позволит быстрее понять, что проблема глобальная, а не только «у нас всё упало» — и не тратить время на поиск несуществующих багов в своём коде.
4. Имейте план коммуникаций с пользователями
Людям обычно всё равно, кто виноват — DDoS, Cloudflare или «космические лучи». Им важно:
- своевременное признание проблемы;
- ориентир по масштабам и срокам;
- информация о временных обходных путях (мобильное приложение, альтернативные каналы заказа, офлайн-точки и т.п.).
Для инженеров и SRE
1. Относитесь к внутренним конфигурациям как к недоверенным данным
Любой конфиг, который меняет поведение ядра системы, должен:
- проходить строгую валидацию по схеме (JSON Schema, Protobuf и т.п.);
- иметь лимиты по размеру и количеству элементов;
- тестироваться на канареечных развёртываниях с автоматическим откатом по аномалиям.
Принцип «доверяй, но проверяй» работает и в коде — даже если данные приходят из «своего» сервиса.
2. Проектируйте fail-soft, а не fail-hard
Модули вроде Bot Management, экспериментальных фич, сложной аналитики должны уметь аккуратно отключаться при ошибках, не обрушивая вместе с собой основной функционал (обслуживание запросов).
Fail-soft (мягкий отказ) — это когда система продолжает работать с ограниченным функционалом при частичном отказе компонентов, вместо полного падения.
3. Перепроверьте скрытые допущения в запросах к базам и сервисам
Всё, что полагается на «по умолчанию у нас всегда одна база / один тип записей / одна конфигурация», следует рассматривать как потенциальную мину замедленного действия — особенно если вокруг ведутся работы по изменению прав и архитектуры.
Проверьте старый код на предмет «что будет, если окружение изменится?»
4. Проводите регулярные учения
Отыграйте всей командой аварийные сценарии:
- «упал CDN»;
- «сломался DNS-провайдер»;
- «отрубился Bot Management»;
- «главная база данных недоступна».
Все эти сценарии должны быть не сюрпризом, а отрепетированной рутиной. Только так команда научится действовать быстро и слаженно в реальном инциденте.
Для российских проектов
1. Оценивайте не только технический, но и регуляторный риск Cloudflare
На одной чаше весов:
- претензии РКН к TLS ECH и рекомендации отказаться от Cloudflare;
- включение в реестр ОРИ и связанные с этим обязательства;
- фактическое ограничение трафика с июня 2025 года.
Это не баг, а политико-техническая реальность, которая вряд ли изменится в обозримом будущем.
2. Если ваша основная аудитория — в РФ, multi-CDN и/или отдельный стек под Россию — де-факто необходимость
Один из разумных подходов:
- держать инфраструктуру для российской аудитории на локальных CDN и хостингах (например, облачные провайдеры с инфраструктурой в РФ);
- а для остального мира использовать Cloudflare и другие глобальные решения;
- использовать geo-routing (географическую маршрутизацию): российские пользователи идут через российский CDN, остальные — через Cloudflare.
3. Считайте стоимость миграции заранее
Переезд с Cloudflare «в пожарном режиме» — когда он одновременно испытывает глобальные сбои и попадает под локальные ограничения — будет дороже и больнее, чем планомерный переход по собственному графику.
Заложите в бюджет:
- время инженеров на миграцию;
- возможное увеличение затрат на CDN;
- временное снижение производительности;
- дополнительные инструменты мониторинга и защиты.
Вместо заключения
Авария 18 ноября — отличный учебный кейс для инженеров и управленцев.
Технически — это история про ClickHouse, один запрос к
system.columns, конфигурационный файл для Bot Management и Rust-код сunwrap(), который превратил превышение лимита в массовые 5xx по всему миру.Системно — напоминание, насколько интернет завязан на нескольких инфраструктурных игроков, и как ошибка в одном месте может повлиять на десятки тысяч независимых сервисов.
Для России — дополнительный маркер того, что технические риски здесь накладываются на регуляторные: Cloudflare одновременно и критически важен для быстрой и безопасной работы сайтов, и находится под серьёзным давлением со стороны государства.
Для бизнеса вывод максимально приземлённый: если вы завязаны на интернет, вы уже завязаны на чужую инфраструктуру. Значит, план «что мы делаем, когда она падает или ограничивается» — обязательная часть архитектуры, наравне с бэкапами и мониторингом.
Никакая компания не застрахована от ошибок. Cloudflare — один из самых надёжных и профессиональных игроков на рынке, но даже у них случаются такие сбои. Это не повод отказываться от использования CDN и защитных сервисов, но отличный повод задуматься о резервировании критической инфраструктуры и планах на случай её отказа.
Глоссарий основных терминов
Для тех, кто хочет лучше разобраться в технических деталях:
CDN (Content Delivery Network) — сеть серверов, распределённых географически, которые кешируют и доставляют контент пользователям с ближайшего узла.
DDoS (Distributed Denial of Service) — атака, при которой множество компьютеров одновременно отправляют запросы на сервер, перегружая его и делая недоступным для нормальных пользователей.
TTL (Time To Live) — время жизни DNS-записи; определяет, как долго информация хранится в кеше до следующего обновления.
Origin — исходный сервер, на котором физически хранится сайт, в отличие от CDN-узлов.
WAF (Web Application Firewall) — межсетевой экран для веб-приложений, защищающий от типичных атак (SQL-инъекции, XSS и др.).
Прокси-сервер (Proxy) — промежуточный сервер, через который проходят запросы между клиентом и целевым сервером.
Постмортем (Post-mortem) — детальный разбор инцидента после его устранения; документ, описывающий что пошло не так, почему и как это исправить.
SRE (Site Reliability Engineering) — инженерная дисциплина, применяющая принципы разработки ПО к задачам эксплуатации инфраструктуры.
Panic — в языке программирования Rust это аварийное завершение программы при критической ошибке, когда продолжение работы невозможно.
ClickHouse — колоночная СУБД для аналитики больших данных с открытым исходным кодом.
Feature (признак) — характеристика, используемая в машинном обучении для принятия решений.
Graceful degradation (изящная деградация) — способность системы продолжать работать с ограниченным функционалом при частичном отказе компонентов.
Canary deployment (канареечное развёртывание) — метод развёртывания, при котором обновление сначала выкатывается на небольшую часть инфраструктуры для проверки.
Throttling (ограничение трафика) — искусственное замедление или обрезание передачи данных.
Edge (граничные узлы) — серверы сети, расположенные близко к конечным пользователям.
Geo-routing (географическая маршрутизация) — направление трафика на разные серверы в зависимости от географического положения пользователя.
Дополнительное чтение
Для тех, кто хочет глубже понять темы, затронутые в статье:
Об инцидентах и их разборе
- Google SRE Book — бесплатная книга от Google о том, как строить надёжные системы
- Incident Review and Postmortem Best Practices — как правильно проводить постмортемы
О централизации интернета
- “The Internet Is Rotting” — статья The Atlantic о хрупкости современной интернет-инфраструктуры
- Отчёты о предыдущих крупных сбоях: AWS (2017), Fastly (2021), CrowdStrike (2024)
О технологиях защиты приватности
- TLS Encrypted Client Hello (ECH) — подробное объяснение технологии от Cloudflare
- eSNI/ECH and Internet Censorship — статья Electronic Frontier Foundation
О российском интернет-регулировании
- Официальные сообщения Роскомнадзора и ведомственные издания
- Аналитические материалы профильных IT-изданий о развитии регулирования в РФ
Источники
Financial Times: ChatGPT and X hit by outage at online security group Cloudflare
AP News: Cloudflare resolves outage that impacted thousands, ChatGPT, X and more
Пикабу: Роскомнадзор против TLS ECH: как технология Cloudflare стала камнем преткновения в Рунете
Ведомости: Роскомнадзор внес Cloudflare в реестр организаторов распространения информации
Interfax: Cloudflare принудительно включена в реестр организаторов распространения информации
The Cloudflare Blog: Russian Internet users are unable to access the open Internet
BleepingComputer: Russia’s throttling of Cloudflare makes sites inaccessible
ICT-Online: Эксперты оценили последствия рекомендации РКН отказаться от Cloudflare
Statusfield: Is Cloudflare Down? Current Cloudflare Status & Outages
Материал подготовлен на основе официальных постмортемов, отчётов СМИ и анализа технической документации. Все технические детали взяты из публичных источников и официальных заявлений компаний.