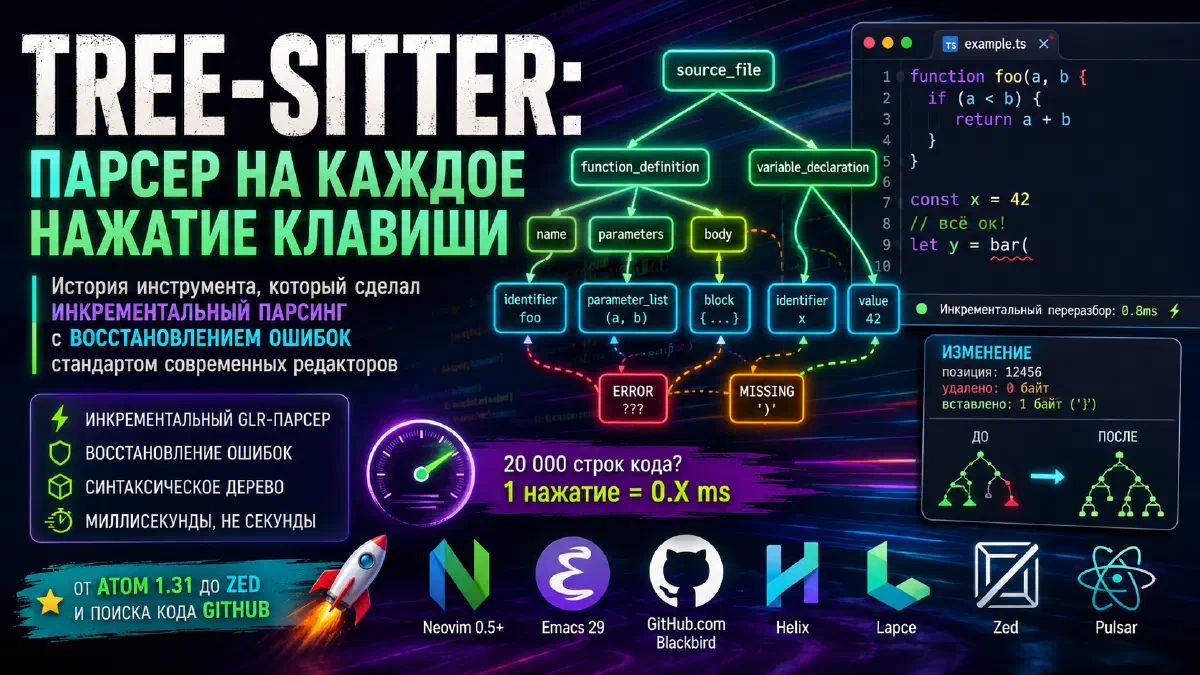
Tree-sitter: парсер на каждое нажатие клавиши
Когда вы правите файл на двадцать тысяч строк TypeScript в современном редакторе, с каждым нажатием клавиши под капотом происходит маленькое инженерное чудо. Парсер языка разбирает изменённую часть файла, обновляет синтаксическое дерево, и редактор успевает за миллисекунды подсветить код, обновить outline, показать диагностику, отрисовать новый кадр — без видимых задержек на ваш ввод.
Технология, которая это делает, называется Tree-sitter. Она умеет не разбирать файл заново при каждом изменении: получив редактирование, Tree-sitter понимает, какая именно часть синтаксического дерева затронута, и переразбирает только её. Всё, что не задето правкой, переиспользуется как есть.
Это давняя мечта инструментальной разработки. Десятилетиями редакторы решали задачу подсветки синтаксиса костылями: либо медленно перепарсивали файл целиком (страдает скорость), либо использовали поверхностные регулярки на каждую строку (страдает точность). Tree-sitter впервые дал способ иметь и точность настоящего парсера, и скорость, достаточную для интерактивной работы. Это изменило мир редакторов — и в 2026 году Tree-sitter стоит в Neovim, в Emacs 29, на GitHub.com, в новых редакторах Helix, Lapce, Zed, в форке Atom под именем Pulsar, в десятках инструментов разработки.
Этот пост — история Tree-sitter. Я расскажу, что было до него (TextMate-грамматики и их многолетние мучения), как Макс Брунсфельд в 2013 году начал писать Tree-sitter параллельно со своей основной работой, и как через пять лет проект стал стандартом редактора Atom. Объясню архитектуру (инкрементальный GLR-парсер с восстановлением ошибок) и почему это правильное архитектурное решение для задачи. Доберусь до Neovim 0.5, Emacs 29, GitHub code search Blackbird. И в финале вы узнаете что Tree-sitter делает, чего не делает, и где он точно не справится.
Это технический пост, и местами я буду углубляться в детали. Но идеи, которые в нём описываются, важны не только для тех, кто пишет редакторы — они показывают, почему простая на первый взгляд задача (подсветить код в окне) на самом деле потребовала нескольких десятилетий инженерного развития, пока её не решили правильно.
1. До Tree-sitter: эпоха TextMate-грамматик
С середины 2000-х и примерно до 2018 года стандартом подсветки синтаксиса в редакторах кода были TextMate-грамматики. Их формат возник в редакторе TextMate Аллана Одгаарда (Allan Odgaard, 2004 год, macOS). Сам TextMate был культовым редактором середины 2000-х, и его подход к подсветке оказался настолько практичным, что его скопировали Sublime Text, Visual Studio Code, GitHub Linguist (тот, что подсвечивает синтаксис файлов у вас в репозитории), и многие другие.
TextMate-грамматика — это plist или JSON-файл с регулярными выражениями. Грамматика задаёт паттерны вида:
{
"name": "keyword.control.javascript",
"match": "\\b(if|else|while|for|return)\\b"
}
Или более сложные, с парными begin/end:
{
"name": "string.quoted.double.javascript",
"begin": "\"",
"end": "\"",
"patterns": [{ "include": "#string-escape" }]
}
Редактор пробегает по тексту, применяет паттерны, расставляет «scope» (категории) на каждом символе. Категории вроде keyword.control.javascript, string.quoted.double.javascript, comment.line.double-slash потом отображаются разными цветами в зависимости от темы.
Это работало. Но у TextMate-грамматик было четыре больших проблемы.
Первая — точность. Регулярные выражения работают только в пределах одной строки. Если у вас многострочный комментарий или строка с переносами, грамматика начинает выкручиваться через begin/end с продолжением состояния. Это работает, но плохо: малейшая ошибка в исходнике, и подсветка «уезжает» до конца файла.
Вторая — невозможность сделать настоящую структуру. TextMate-грамматика подсвечивает токены, но не строит дерево. Она не знает, что function foo(a, b) { return a + b } — это объявление функции с двумя параметрами и телом. Она знает только: тут есть слово function, дальше идентификатор, потом скобки. Это значит, что любая фича, требующая понимания структуры — переход к определению, выделение функции целиком, рефакторинг — не получается из TextMate-грамматики.
Третья — сопровождаемость. Регулярки в TextMate-грамматиках сложных языков (TypeScript, C++, Rust) превращаются в монстров из сотен правил с десятками capture-групп и хитрых escape-последовательностей. Канонический пример — TypeScript TmLanguage, у которого в репозитории больше пятисот открытых issues с багами в подсветке синтаксиса. Поддерживать такую грамматику — отдельная инженерная боль.
Четвёртая — производительность на больших файлах. Если файл большой, и в нём есть длинные строки или сложные конструкции, regex-парсинг может занимать заметное время. На многотысячных файлах подсветка иногда отстаёт от ввода.
К середине 2010-х индустрия понимала, что TextMate-подход — это тупик. Нужно что-то другое.
2. Макс Брунсфельд и старт проекта
В 2013 году в Pivotal Labs работал программист по имени Макс Брунсфельд. Pivotal — известная консалтинговая компания, специализирующаяся на agile-разработке и Ruby-проектах. Брунсфельд писал на Ruby, JavaScript, занимался разными клиентскими проектами. И в свободное от работы время он начал работу над Tree-sitter — библиотекой, которая должна была правильно решить проблему подсветки кода.
Первый коммит в репозиторий Tree-sitter датируется 6 ноября 2013 года. На тот момент это был сторонний проект — Брунсфельд писал его «по ночам и выходным». Он не был частью никакой большой компании, и не был обеспечен корпоративными ресурсами. Это была идея одного программиста, который заметил конкретную инженерную задачу и решил её решить.
Цель Брунсфельда была такая: построить настоящий парсер, который строит синтаксическое дерево, и при этом достаточно быстрый, чтобы работать в редакторе в реальном времени. Он понимал, что классические парсер-генераторы (Yacc, Bison, ANTLR) для этой задачи не подходят, потому что дают слишком медленные парсеры, они не умеют ни восстанавливаться после ошибок, ни инкрементально переразбирать изменившиеся куски.
К 2013 году Брунсфельд перешёл в команду Atom в GitHub. Atom — это новый редактор, который GitHub запускал как попытку конкурировать с Sublime Text и подготовиться к веб-эпохе разработки. Atom был построен на Electron (первая широкая известная реализация подхода «нативное приложение на веб-технологиях»), и его команда была заинтересована во всех способах сделать подсветку синтаксиса лучше. Идея Брунсфельда про Tree-sitter оказалась в нужном месте в нужный момент.
Следующие пять лет Брунсфельд работал в команде Atom и параллельно развивал Tree-sitter. Большая часть времени уходила на алгоритмическое исследование — какой именно тип парсера лучше подходит для инкрементальной задачи. Перебиралось несколько вариантов: PEG, LL(*), классический LR. В итоге Брунсфельд остановился на обобщённом LR (GLR), который был расширен инкрементальностью и восстановлением ошибок.
3. Atom 1.31 и Strange Loop 2018
Публичный анонс Tree-sitter состоялся 26 сентября 2018 года, когда вышел релиз Atom 1.31. В этой версии Tree-sitter был включён по умолчанию (на бета-канале) как новая система подсветки и индентации. Поддерживались одиннадцать языков: Bash, C, C++, ERB, EJS, Go, HTML, JavaScript, Python, Ruby, TypeScript. GitHub опубликовал в своём блоге пост «Atom understands your code better than ever before», в котором объяснил идею.
Через несколько дней Брунсфельд представил Tree-sitter на конференции Strange Loop 2018 в Сент-Луисе. Его доклад называется «Tree-sitter: a new parsing system for programming tools» и до сих пор остаётся самой цитируемой канонической презентацией Tree-sitter. Если вы хотите глубоко понять, как Tree-sitter устроен изнутри, этот доклад — лучшая точка входа.
Strange Loop — конференция, известная тем, что туда отбирают доклады про действительно интересные идеи, а не про практические инструменты. Tree-sitter выглядел в этом контексте отлично: это был не «новый редактор», а новая алгоритмическая идея, реализованная как библиотека.
Через пару лет, к 2020-му, экосистема вокруг Tree-sitter начала расти быстро. Появились грамматики для десятков языков, написанные сторонними разработчиками. Стали появляться плагины интеграции с другими редакторами. И вот тут начинается главное.
4. Архитектура: инкрементальный GLR
Прежде чем рассказать про распространение Tree-sitter в Neovim, Emacs и GitHub, разберёмся с тем, как он работает.
Tree-sitter — это инкрементальный GLR-парсер с восстановлением ошибок. Каждый из этих трёх кусков названия важен.
GLR (Generalized LR) — это обобщение классического LR-парсинга, придуманного Кнутом в 1965-м. Обычный LR парсит детерминированно: на каждом шаге у него один стек, и он либо сдвигает токен, либо сворачивает уже накопленную последовательность по правилу. Если возникает конфликт (можно сделать и то, и другое) — обычный LR умирает или требует переписать грамматику.
GLR в той же ситуации разветвляет стек и пробует обе возможности параллельно. Если одна из веток заходит в тупик, она отбрасывается. Если обе доходят до конца входа, грамматика неоднозначна, и парсер возвращает обе версии дерева. GLR придуман в 1980-х (Масару Томита, статья 1986 года), и до Tree-sitter его использовали в основном в академических компиляторах и для парсинга естественных языков.
Tree-sitter взял GLR, потому что он толерантен к неоднозначностям грамматики. Реальные языки программирования часто содержат локально-неоднозначные конструкции — например, a < b > (c) в C++ может быть и сравнением, и шаблонной инстанциацией, в зависимости от контекста. GLR может рассмотреть оба варианта и выбрать тот, который согласуется с дальнейшим текстом.
Инкрементальность — главная фишка Tree-sitter. Когда вы редактируете файл, парсер не разбирает его заново. Tree-sitter получает редактирование (edit) в виде «начиная с символа X, удалено N байт, вставлено M байт». На основе этого редактирования он понимает, какие узлы старого дерева точно не изменились, и переиспользует их как есть. Только узлы, которые попадают в затронутую область или могут быть затронуты через изменение контекста, разбираются заново.
Это даёт огромную экономию. Парсинг файла на двадцать тысяч строк с нуля может занять сотни миллисекунд. Инкрементальный переразбор после одного нажатия клавиши — обычно меньше миллисекунды. На бенчмарках на типовом железе полный парсинг C-файла на десять тысяч строк занимает меньше ста миллисекунд, а инкрементальный — около миллисекунды.
Инкрементальность работает за счёт того, что синтаксические деревья в Tree-sitter иммутабельны и разделяемы. Когда вы редактируете файл, старое дерево не меняется. Создаётся новое дерево, которое указывает на узлы старого там, где они не изменились. Это та же идея, что и persistent data structures в Clojure (которые я уже упоминал в посте про Lisp) — экономия за счёт переиспользования общих частей.
5. Восстановление ошибок
Третий кусок — восстановление после ошибок. Это критично для редактора, потому что код в процессе ввода почти всегда синтаксически некорректен. Когда вы только напечатали function foo(a, b и ещё не закрыли скобку, классический парсер скажет «syntax error» и остановится. А редактору в этот момент уже надо подсвечивать слово function как ключевое, идентификатор foo как имя функции, и параметры a, b как параметры.
Tree-sitter решает это через тот же GLR-механизм. При невозможности продолжать парсинг он пробует разные стратегии восстановления: пропустить следующий токен и продолжить; вставить пропущенный токен и продолжить; откатиться назад и попробовать другую интерпретацию. Из этих стратегий выбирается та, которая через несколько токенов даёт «лучший» результат — то есть синтаксически валидное продолжение с минимальным количеством ошибок.
Места, где парсер не смог сойтись на корректное дерево, помечаются специальными узлами ERROR или MISSING. ERROR — это «здесь было что-то, что не подошло ни под одно правило». MISSING — «здесь должно было быть что-то, чего нет» (например, закрывающая скобка). Эти узлы видны в дереве, и потребитель (редактор, линтер, любой инструмент) может с ними как-то работать: показать пользователю красную волну, дать подсказку, попробовать автокомплит.
Любопытно, что в Tree-sitter нет формального академического описания алгоритма восстановления. Главным источником остаётся доклад Брунсфельда на Strange Loop и сам код. В тикетах проекта периодически возникают просьбы написать аккуратную статью или хотя бы развёрнутую документацию, но за восемь лет ни у кого до этого так и не дошли руки — алгоритм работает в продакшене у миллионов пользователей, так что приходится читать исходники.
6. Грамматики на JavaScript
Чтобы добавить поддержку нового языка, нужно написать грамматику для Tree-sitter. Это делается на специальном JavaScript-DSL, описанном в файле grammar.js.
Выглядит это так:
module.exports = grammar({
name: 'mylang',
rules: {
source_file: $ => repeat($._definition),
_definition: $ => choice(
$.function_definition,
$.variable_declaration
),
function_definition: $ => seq(
'function',
field('name', $.identifier),
field('parameters', $.parameter_list),
field('body', $.block)
),
parameter_list: $ => seq(
'(',
optional(commaSep1($.identifier)),
')'
),
block: $ => seq('{', repeat($._statement), '}'),
identifier: $ => /[a-zA-Z_][a-zA-Z0-9_]*/,
// ...
}
});
Это компактнее и приятнее, чем традиционные BNF в Yacc. Доступны функции seq (последовательность), choice (выбор), repeat (повторение), optional, prec (приоритет), token, field (именованные поля для узлов), и ещё несколько. Грамматика — это обычный JavaScript-код, и в ней можно использовать любые JS-функции для генерации правил (типа commaSep1 в примере выше — это утилита, которая разворачивается в seq($.elem, repeat(seq(',', $.elem)))).
Команда tree-sitter generate парсит grammar.js, прогоняет через Node, получает промежуточное JSON-представление, и компилирует это в C-код парсера. Сам C-код длинный (десятки тысяч строк для крупного языка) и нечитаемый, но это машинно-сгенерированный код — его никто не правит руками.
Большая часть синтаксиса языков описывается грамматикой целиком. Но есть конструкции, которые контекстно-зависимы — например, значимые отступы в Python, где открытие и закрытие блоков определяются изменением уровня отступа. Такие штуки описываются в Tree-sitter через external scanner — ручной C/C++-код, который подключается к парсеру и решает контекстно-зависимые задачи. Это компромисс, но он работает.
На сегодня (2026 год) на GitHub есть более 300 грамматик для разных языков. Большинство сделано сообществом, флагманские (C, Python, JavaScript, Rust, Go) — в основной организации tree-sitter на GitHub. Качество грамматик сильно разное: некоторые отлично сделаны и быстро работают, другие имеют проблемы с производительностью или с покрытием экзотических конструкций.
7. Neovim 0.5: революция в редакторе
2 июля 2021 года вышел релиз Neovim 0.5. Это был один из самых значимых релизов в истории редактора за последние десять лет. Главное нововведение — встроенная поддержка Tree-sitter через новый Lua-API.
Чтобы понять, почему это важно, надо вспомнить контекст. Neovim — современный форк классического Vim, который начался в 2014 году с целью переписать Vim под современную инфраструктуру (асинхронные API, нативная поддержка Lua, встроенный LSP-клиент, нативные плагины). К 2020 году Neovim уже был зрелым редактором, и его сообщество искало способы сделать подсветку и навигацию по коду лучше, чем в классическом Vim, который десятилетиями использовал regex-based подсветку (в Vim она называется «syntax highlighting» и состоит из тысяч строк регулярок в файлах *.vim).
Tree-sitter в Neovim 0.5 был экспериментальным, с регрессиями и багами. Но направление было задано, и сообщество подхватило. Появился плагин nvim-treesitter — обёртка, которая ставит грамматики, конфигурирует подсветку, добавляет навигацию по структуре кода. К 2022–2023 годам этот плагин стал стандартом — практически каждый серьёзный пользователь Neovim его устанавливает.
С появлением Tree-sitter в Neovim родилась целая волна Lua-плагинов, которые используют синтаксическое дерево для умных операций: nvim-treesitter-textobjects (выделение целых функций, классов, блоков), treesitter-context (показ контекста текущей функции в виде «прилипшего» к верху окна), nvim-treehopper (быстрая навигация по узлам дерева), и десятки других. Это новая инструментальная экосистема, которой в классическом Vim не было.
8. Emacs 29: встроенная поддержка
Emacs прошёл тот же путь чуть позже. В июле 2023 года вышел Emacs 29 — первый релиз, в котором Tree-sitter стал встроенной частью редактора.
Модуль называется treesit (написан на C, плюс Lisp-обвязка). Грамматики подключаются как динамические библиотеки через команду treesit-install-language-grammar. В Emacs 29 встроены *-ts-mode для шестнадцати языков: C, C++, C#, Java, Rust, Go, Python, JavaScript, TypeScript, JSON, YAML, TOML, CSS, Bash, Dockerfile, CMake.
До этого в Emacs существовал сторонний пакет emacs-tree-sitter от Туан-Ань Нгуена (Tuấn-Anh Nguyễn), который сделал колоссальную работу по добавлению Tree-sitter в Emacs ещё в 2019–2020 годах. С релизом Emacs 29 этот пакет теперь рекомендует пользователям перейти на встроенный treesit — но именно работа Нгуена показала, что Tree-sitter в Emacs возможен и желанен, и подготовила почву для официальной интеграции.
В посте про Emacs я уже упоминал, что Emacs 29 принёс два важных нововведения: нативную компиляцию Emacs Lisp и Tree-sitter. Эти изменения сильно подтянули современный Emacs к уровню современных редакторов вроде VSCode — там, где раньше Emacs выглядел архаично, теперь он стал конкурентоспособен.
9. GitHub.com: новый поиск кода
Параллельно с интеграцией в редакторы Tree-sitter попал в сам GitHub.com. В 2022 году в публичную бету вышел новый поиск кода — внутренний кодовый проект под кодовым именем Blackbird. В 2023-м (полный анонс — пост «The technology behind GitHub’s new code search» от 6 февраля 2023) он стал общедоступным.
Blackbird — это система поиска по коду, которая работает на всех публичных репозиториях GitHub (это десятки терабайт исходников на сотнях языков). И для того, чтобы поиск был семантическим, то есть искал не просто текст, а функции, классы, переменные с пониманием их роли, нужен парсер на каждый язык.
GitHub выбрал Tree-sitter. В посте про архитектуру это написано прямо: «Enry и Tree-sitter питают language detection и symbol extraction Blackbird». То есть когда вы ищете на GitHub function MyFunc, поиск точно знает, что MyFunc — это имя функции, а не комментарий или строковый литерал. Это знание берётся из синтаксического дерева, построенного Tree-sitter.
Параллельно с Blackbird GitHub разработал Stack Graphs — фреймворк для точной навигации по коду (precise code navigation), который надстраивается над Tree-sitter. Stack Graphs решает задачу разрешения имён: когда вы кликаете на использование переменной, перейти к её определению, даже через несколько уровней импортов, наследований, скоупов. Это серьёзная задача, и Stack Graphs её решает поверх синтаксических деревьев Tree-sitter.
Параллельно GitHub в 2025 году архивировал свой старый проект Semantic — Haskell-библиотеку для семантического анализа кода, которая до Tree-sitter была основой code navigation на GitHub. То есть Tree-sitter не просто добавлен — он заменил предыдущее поколение инструментов в инфраструктуре одного из крупнейших сайтов разработки.
10. Новые редакторы: Helix, Lapce, Zed
К началу 2020-х Tree-sitter стал настолько хорошим решением, что новые редакторы, появившиеся в эти годы, строились с Tree-sitter в качестве центрального компонента подсветки и навигации.
Helix — модальный редактор на Rust, появившийся в 2020-м, вдохновлённый Vim и Kakoune. Tree-sitter в Helix — центральный движок подсветки, отступов и структурного редактирования. Helix не поддерживает Vim-плагины — у него своя архитектура, и Tree-sitter в неё встроен глубоко, не как опция, а как фундамент.
Lapce — графический редактор на Rust, использующий ту же Tree-sitter-реализацию, что и Helix (через MPL-лицензию). Lapce — попытка сделать «VSCode на Rust», и Tree-sitter там для подсветки и навигации.
Zed — отдельная история. Zed основали в 2021 году трое программистов из бывшей команды Atom: Макс Брунсфельд (тот самый создатель Tree-sitter), Натан Собо и Антонио Скандурра. Zed — это попытка с нуля сделать редактор, оптимизированный под производительность: написан на Rust, использует GPU для рендеринга, ориентирован на совместное редактирование. Tree-sitter в Zed — естественная часть архитектуры, и Брунсфельд продолжает его развивать прямо из своей роли соучредителя.
Zed был запущен публично в 2023-м, и за два года команда успела собрать в общей сложности около $42 млн венчурных инвестиций (в том числе крупный раунд от Sequoia в ноябре 2024-го). Это уже серьёзная редакторская компания, и она строится вокруг Tree-sitter как одной из своих ключевых технологий.
И тут возникает интересная картинка. Tree-sitter, начавшийся как сторонний проект одного программиста в Pivotal Labs в 2013 году, через десять лет стал технической основой нескольких новых редакторов, инфраструктуры GitHub и встроенной частью Emacs и Neovim. Это редкая история про то, как алгоритмическая идея превращается в стандарт индустрии.
Любопытно, что VSCode — самый популярный редактор мира — на Tree-sitter в основной подсветке до сих пор не перешёл. VSCode продолжает использовать TextMate-грамматики (со всеми их проблемами) для большинства языков. Tree-sitter применяется в нём только в отдельных расширениях. Это и есть лучшее напоминание о том, что универсального стандарта парсинга в индустрии всё ещё нет: даже самый массовый редактор не унифицировал свой стек на Tree-sitter — слишком много накопившегося легаси-кода и расширений, которые пришлось бы переписывать.
11. Что Tree-sitter не делает
Tree-sitter — отличный инструмент, но у него есть принципиальные ограничения, которые важно понимать.
Tree-sitter строит конкретное синтаксическое дерево (CST), а не абстрактное (AST). Разница такая: CST содержит все токены исходного кода, включая скобки, точки с запятой, ключевые слова, комментарии. AST — упрощённое дерево, в котором скобки и точки с запятой выкинуты, оставлена только семантическая структура. Для редакторов CST идеально: вы можете точно восстановить позицию каждого узла в исходнике, подсветить его, дать пользователю выделить целую функцию вместе со скобками. Но для компилятора CST избыточен — компилятор обычно хочет AST, и Tree-sitter не даёт его напрямую.
Tree-sitter не делает семантический анализ. Он не знает, что переменная x объявлена выше и сейчас используется. Он не знает типов. Он не знает, к какому классу относится метод. Всё это — задача надстроек (как Stack Graphs у GitHub, как LSP-сервер для каждого языка). Tree-sitter — это только синтаксис.
Tree-sitter не подходит для компилятора. Главная причина — он может «проглатывать» невалидный синтаксис и не помечать его как ошибку, чтобы продолжать парсинг. Для компилятора это катастрофично: он не должен принимать неверный код как валидный. Поэтому реальные компиляторы (Rust, Go, TypeScript) всё равно используют свои собственные парсеры — обычно рукописный рекурсивный спуск.
Грамматики сложно писать. JavaScript-DSL в целом понятный, но контекстно-зависимые конструкции требуют ручного внешнего сканера на C. Кроме самой грамматики, под каждый язык пишутся запросы подсветки — отдельные файлы, в которых конкретные узлы дерева помечаются именами вроде @function.call, @variable.builtin, @string и так далее. По этим именам редактор уже решает, каким цветом красить кусок текста. Беда в том, что единого словаря этих имён нет: Zed, Neovim и Helix используют немного разные наборы — и грамматики приходится править под каждый редактор отдельно.
Инкрементальность не всегда работает идеально. На очень больших файлах с плохо написанной грамматикой переразбор может занимать секунды. Известны кейсы: 1.6 МБ JSON-файл — полный парсинг 1.2 секунды, переразбор 0.7 секунды; 10 МБ C-файл — переразбор около тридцати секунд. Качество грамматики решает: переписывание tree-sitter-haskell с C++ на C дало 52-кратное ускорение. То есть «миллисекундный переразбор» — это честная цифра для нормальных файлов и нормальных грамматик, но бывают и патологические случаи.
12. Что и когда использовать в 2026 году
Если вы в 2026 году хотите использовать Tree-sitter в своём проекте, у вас есть несколько вариантов в зависимости от цели.
Подсветка синтаксиса и структурная навигация в собственном редакторе или IDE. Берите Tree-sitter — это сегодня стандарт. Есть готовые runtime-библиотеки на C, Rust, JavaScript, Python, Go, Java, Haskell. Грамматики для популярных языков уже написаны и поддерживаются сообществом.
Анализ кода в небольшом инструменте (линтер, форматтер, метрики). Tree-sitter — отличный вариант. Вам не нужно писать собственный парсер для каждого языка. Вы берёте существующую грамматику, и через несколько часов работы у вас есть синтаксическое дерево, по которому можно строить любые анализы. Лучше всего на Python (через py-tree-sitter) или Rust.
Подсветка в маленьком GUI или TUI приложении. Tree-sitter работает, но это может быть избыточно. Если вам нужно подсветить только два-три простых языка, TextMate-грамматики через vscode-textmate или просто свои regex-правила могут оказаться проще.
Парсер для собственного компилятора. Tree-sitter — не лучший выбор. Делайте рукописный рекурсивный спуск: именно так устроены парсеры всех современных серьёзных компиляторов (Rust, Go, TypeScript, Swift). Tree-sitter удобен для редакторов, потому что прощает ошибки; компилятор не должен прощать ошибки.
Семантический анализ (резолв имён, типы, кросс-файловая навигация). Tree-sitter сам этого не делает, но даёт фундамент. Сверху вам нужны Stack Graphs (от GitHub), LSP-сервер целевого языка, или своя реализация.
Интеграция Tree-sitter в существующий редактор. Если вы пишете плагин для Neovim, Emacs или VSCode и хотите использовать дерево синтаксиса — у Tree-sitter есть API во всех этих экосистемах. Это самый быстрый способ начать.
13. Финал: парсер, ставший инфраструктурой
Tree-sitter — это редкая история про то, как инженерное усилие одного программиста, работавшего параллельно с основной работой, через десять лет становится стандартом индустрии.
В 2013-м Макс Брунсфельд начал писать инкрементальный парсер по вечерам, в свободное от Pivotal Labs время. В 2018-м Tree-sitter появился по умолчанию в Atom. В 2021-м — стал частью Neovim. В 2023-м — встроен в Emacs и в инфраструктуру поиска кода GitHub. В 2024-м — основа нового редактора Zed, на который Брунсфельд получил $32 миллиона венчурного капитала.
И при всём этом сам Tree-sitter остаётся открытой библиотекой на C с MIT-лицензией, в которую любой желающий может прислать pull request. Это та же модель, что и у Linux, Git, Python — инфраструктура, которой пользуются все, развивается сообществом без жёсткого корпоративного контроля.
Если вы программист, ежедневно работаете в современном редакторе и видите подсветку синтаксиса, дерево навигации, переход к определению, контекстное автодополнение — высока вероятность, что под капотом этих фич работает Tree-sitter. Вы об этом не думаете, потому что хорошая инфраструктура невидима. Но если её убрать, мы вернёмся в эпоху TextMate-грамматик с их регулярками, странной подсветкой и невозможностью семантического анализа.
Рядом стоит ещё одна большая инфраструктурная штука современной разработки — LSP (Language Server Protocol), который занимается уровнем выше Tree-sitter: семантикой языков, навигацией по символам, диагностикой. Tree-sitter и LSP отлично дополняют друг друга, и сегодня в любом современном редакторе они работают в связке. А что происходит после парсера — как из дерева получается машинный код, — это уже тема для отдельного большого поста про компиляторы целиком.
Дополнительное чтение
Главные источники
- Tree-sitter — сайт проекта
- Tree-sitter на GitHub
- Атом-блог: «Atom understands your code better than ever before» (2018)
- GitHub blog: «The technology behind GitHub’s new code search» (6 февраля 2023)
- GitHub blog: «Introducing stack graphs»
Видео
📺 Max Brunsfeld, «Tree-sitter — a new parsing system for programming tools» (Strange Loop 2018) — каноническая презентация автора. Лучшая точка входа в идеи Tree-sitter.
📺 Tree-sitter в Neovim — обзор и настройка
Грамматики и инструменты
- Список флагманских грамматик — основная организация на GitHub.
- tree-sitter-language-pack — пак с 300+ грамматиками для разных языков.
- nvim-treesitter — основной плагин для Neovim.
- emacs-tree-sitter — исторический пакет для Emacs до версии 29.
Применение
- Neovim 0.5 release notes (июль 2021)
- Tree-sitter in Emacs 29 and Beyond — Yuan Fu — подробный пост про интеграцию в Emacs 29.
- Helix Tree-sitter integration — гайд по добавлению языков в Helix.
- Zed Team — команда Zed, включая Брунсфельда.
Критика и ограничения
- Issue #224: Document the error-recovery algorithm — обсуждение восстановления ошибок.
- Speeding up tree-sitter-haskell 50x — кейс про оптимизацию плохо написанной грамматики.
- Modern Tree-sitter, part 7 — Pulsar blog — серия постов от форка Atom о современных нюансах работы с Tree-sitter.